De derde stap in een DMAIC green belt project (en de eerste stap van de meetfase) is het VALIDEREN VAN HET MEETYSTEEM. Afhankelijk van het type data dat je hebt, gebruik je of een Gage R&R (voor numerieke data) of een Attribute Agreement Analysis (voor discrete data)
Voor Numerieke data doen we de Measurement System Analysis (MSA) stap aan de hand van een GAGE R&R. Deze test meet de Repeatability (herhaalbaarheid) en de Reproducibility (reproduceerbaarheid) van de Gage, een meetinstrument.
De Gage R&R is een percentage dat 3 factoren met elkaar vermenigvuldigd:
(1) de herhaalbaarheid van test gedaan op hetzelfde product sample door dezelfde persoon,
(2) de reproduceerbaarheid tussen testresultaten van verschillende operators,
(3) het verschil tussen operators die dezelfde metingen doen.
De resultaten van de test lees ik persoonlijk het liefst af in de tabel die uit Minitab of JMP komt. De Figuur 3 laat een voorbeeld zien van een tabel als output van minitab. In de bovenste helft van de figuur We zien alle verschillende soorten variatie samengevat in een tabel, de contribution factors van elk van de 3 factoren. Afhankelijk van welk type variatie het hoogst is, kunnen we verbeter acties definiëren.
In de green belt focussen we ons alleen op de bovenste helft van de figuur, en lezen we de contribution variance (VarComp) af van de Gage R&R. In dit voorbeeld is de VarComp-waarde 7.76%. Over het algemeen is een VarComp-waarde van <10% een goed meetsysteem, een waarde tussen de 10 en 20% een acceptabel meetsysteem, en een waarde van >20% onacceptabel.

Figuur 3: Gage R&R tabelweergave van de resultaten.
In het geval van discrete data praten we binnen de MSA-stap over een ATTRIBUTE AGREEMENT ANALYSIS, waarin gekeken wordt of verschillende personen producten indelen in categorische data, waaronder bijvoorbeeld de discrete groepen: zoals ‘ok’ en ‘niet ok’.
In deze analyse selecteer je een groep personen (bijvoorbeeld 3), en laat hen een nauwkeurige set van productsamples beoordelen (tussen de 30 en de 100). De volgorde waarin de samples worden beoordeeld staat vast en elk persoon krijgt de reeks aan samples meerdere keren aangeboden (bijvoorbeeld 3 keer). Belangrijk is om samples te kiezen die op de rand van goed- en afkeur liggen, zodat het niet te overduidelijk is of de sample goedgekeurd of afgekeurd zou moeten worden. De resultaten van de atribute agreement analysis zijn tweevoudig. De eerste helft van de resultaten beschrijft de herhaalbaarheid (de repeatability) van de meting. In dit geval laat een grafiek zien in hoeverre de verschillende mensen die mee hebben gedaan in de studie dezelfde samples hetzelfde beoordeelden.
De tweede helft van de resultaten van de toets vergelijkt de beoordeling van de medewerkers die van een expert. Hiermee kunnen we beoordelen in hoeverre de meetmethode reproduceerbaar (de reproducibility) is. Figuur 3 laat het resultaat zien van een voorbeeld test waarin 3 mensen de kwaliteit van een winegum testen en uitsorteren op basis van ‘ok’ en ‘niet-ok’. Wat valt op?
De herhaalbaarheid is bij operator 3 het beste. Deze persoon heeft alle samples de verschillende keren dat ze beoordeeld zijn, hetzelfde beoordeeld (zie linkerhelft van figuur 3). Operator 3 heeft ook de hoogste score in vergelijking met de expert. 93% van de waarden van operator 3 kwamen overeen met die van de expert (De blauwe stip op de rechterhelft van figuur 3).
Als doelstelling zou je 80% als waarden willen hebben voor zowel de herhaalbaarheid als de reproduceerbaarheid. Bedenk wel, dat de sample die je hebt genomen op de rand van goed- en afkeur liggen. Dus, wanneer operator 2 slechts 70% dezelfde conclusies heeft getrokken in dit experiment, is er wellicht verbetering wenselijk, maar het zegt niets over hoe deze persoon een hele populatie aan samples beoordeeld.
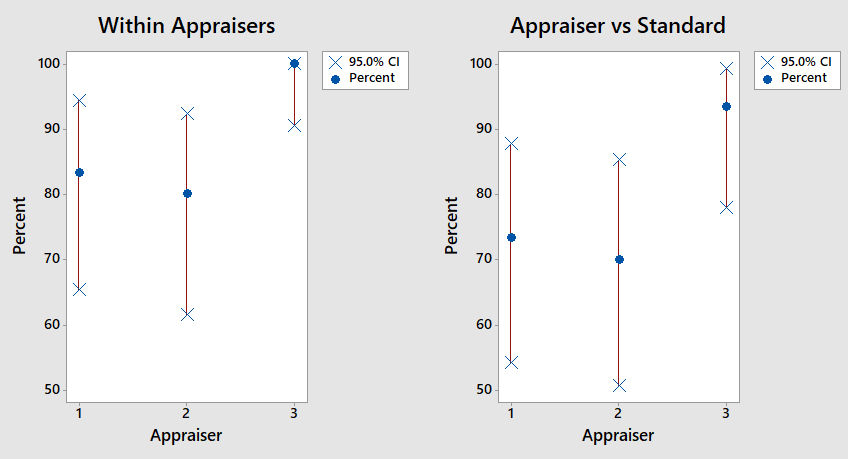
Figuur 3: Attribute Agreement Analysis grafiek.
Een uitgebreidere versie van dit artikel, inclusief productie voorbeelden, vind je in hoofdstuk 5 van het boek: Six Sigma DMAIC.
Ga verder naar: