De tweede stap van een DMAIC project beschrijft het verzamelen van de HUIDIGE KENNIS van de huidige data die we hebben. Afhankelijk van wat voor type data je hebt, kun je voor numerieke data een histogram gebruiken, een scattterplot of matrix plot gebruiken, or een process behavioral chart bekijken. Voor discrete data, of numerieke data met discrete categorieën, kun je een boxplot gebruiken.
DE BOXPLOT is een visuele weergave van een (numerieke) dataspreiding die je kunt gebruiken om verschillende discrete categorieën met elkaar te vergelijken.
Figuur 1 laat een voorbeeld van een boxplot zien en de informatie die we hieruit kunnen afleiden.
De grijze box in het midden van de boxplot representeert 50% van de datapunten die hebt gemeten, met aan de uiteinden de upper- en lower quartile (resp. het 3e en 1e kwartiel). Hoe smaller de box, hoe minder de variatie tussen de datapunten.
De mediaan is weergeven als een zwarte lijn binnen deze grijze box. Dit betekent dat er evenveel datapunten hoger dan deze waarde zijn als dat er lager dan deze waarde zijn.
zowel boven als onder de boxplot zijn de minimum en de maximum waarde weergegeven met horizontale strepen. Deze woorden door een programma als Minitab statistisch berekend.
En zijn namelijk ook outliers weer te geven met een stip buiten deze grenzen. Dit zijn de waarden die onderdeel van je sample data zijn, maar die zover buiten de rest van de set liggen dat ze buiten beschouwing worden gelaten door het rekenprogramma omdat ze anders het totaalbeeld van bijvoorbeeld de boxplot te veel vertekenen.
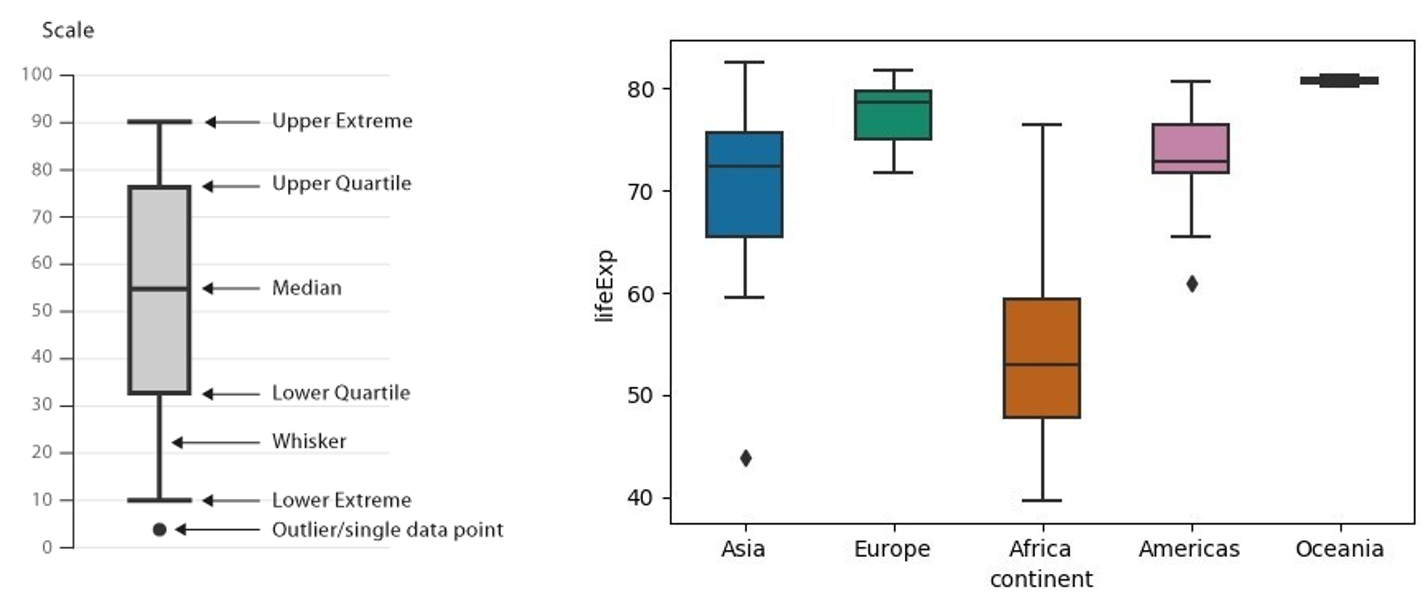
Figuur 1: Boxplot voorbeeld (links) en vergelijkingsvoorbeeld (rechts)
Aan de rechterzijde van figuur 1 zien we een voorbeeld waarbij we verschillende boxplots met elkaar kunnen vergelijken. De discrete data categorieën in dit voorbeeld zijn de continenten waarop we de levensverwachting met elkaar vergelijken. Hieruit kunnen we bijvoorbeeld afleiden dat de mediaan leeftijd in Europa, Azië en (noord en zuid) Amerika veel hoger ligt dan in Afrika. We kunnen echter ook zien dat de spreiding van leeftijd in Afrika veel groter is dan op de andere continenten. Zoals verwacht zijn er ook op dat continent mensen die 75 worden, alleen is het aandeel veel kleiner dan in de Westerse wereld.
Een histogram is een grafische weergave van de verdeling van een reeks van numerieke waarden (y) ten opzichte van 1 x waarden en deze tool is ook al besproken is het artikel over verschillende datatypen. De vorm van de grafiek die we zien helpt ons om een beeld te vormen van de huidige situatie. Vragen als: ‘is de numerieke reeks normaal verdeeld?’ En ‘Hoe groot is de spreiding van de waarden?’ kunnen worden beantwoord. We zullen verderop in dit artikel meer in detail ingaan op het aflezen van capabilities vanuit dit histogram.
Figuur 2 laat een variatie aan verschillende histogrammen zien. Links onder in de figuur zien we een normale verdeling, waarbij de meest voorkomende waarde zich in het midden van en een reeks bevind. De figuur laat zien dat er verschillende andere soorten verdelingen mogelijk zijn. Deze serie artikelen focust zich op statistische toetsen die te gebruiken zijn voor normaal verdeelde data. Voor de andere typen data zijn ook toetsen beschikbaar, maar die zijn buiten de scope voor een Green Belt.
Het histogram vormt de basis voor de capabiliteitsanalyse die we in projectstap 4 zullen tegenkomen.

Figuur 2: verschillende voorbeelden van een histogram.
(BRON: data-to-viz.com)
Waar een histogram een grafische weergave is van een numerieke reeks voor 1 discrete waarde, is een scatterplot een weergave van de correlatie tussen twee numerieke reeksen. Hierdoor kun je in je eerste indruk al zien of er een link tussen de twee variabelen te vinden is. In Figuur 3 zien we 3 voorbeelden van een scatterplot. De linker grafiek laat een positieve correlatie tussen 2 numerieke reeksen zien: de hoger X is, de hoger Y is. De middelste grafiek laat een negatieve correlatie tussen X en Y zien: de hoger X is, de lager de Y-waarde. De rechter grafiek tot slot, laat zien dat er geen correlatie tussen X en Y is, de waarden zijn willekeurig over de grafiek verdeeld.

Figuur 13 Scatterplot examples (BRON: Khan Academy)
Een matrixplot is een verzameling van scatterplots, waarbij we meerdere numerieke reeksen met elkaar kunnen vergelijken. Je kunt dan voor alle mogelijke combinaties van reeksen in één opslag zien of er een relatie bestaat tussen enkelen van die reeksen.
Ga verder naar:
Green Belt DMAIC – Meetsysteemanalyse, Gage R&R, Attribute Agreement Analysis